
Data lineage: what it is and how it works

What is data lineage?
The data lineage feature provides a visualization of your ODS objects (datasets, pages, maps, and charts), how they're related to others objects, where they're being used, and by whom.
Opendatasoft offers two levels of information:
Business lineage: This describes relationships between objects. It provides a high-level view of dependencies between these objects, offering a broad understanding of how different datasets or objects are connected within the platform.
Field-level lineage: This option provides a more detailed view of relationships between objects specifically focusing on the fields linked within these objects. This view emphasizes dependencies at the data field level, offering an in-depth understanding of specific connections between fields in different ODS objects.
You can:
Keep track of your dataset lifecycle
Understand how an object affects or is affected by changes to objects up or downstream from it
Quickly see which datasets are used and how popular they are
Note that the information provided in lineage is not the same as usage volume. The usage volume and the data lineage feature have different purposes. The lineage feature allows you to visualize links between ODS objects regardless of how they are used (download count or number of API calls).
Where do I go to use data lineage?
There are two ways data lineage allows you to examine your datasets and how they're related to other ODS objects. In the back office:
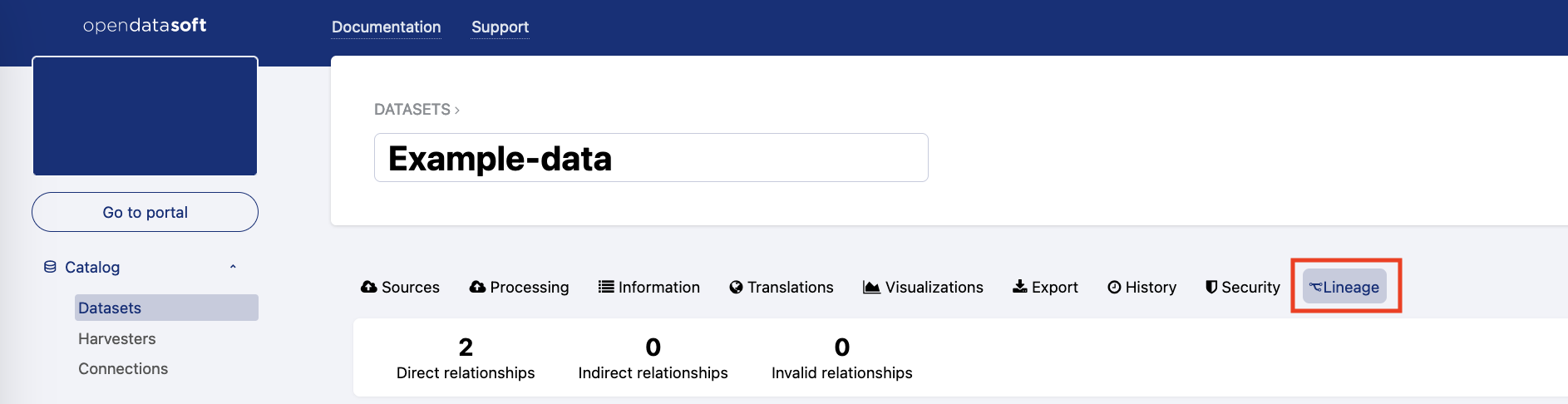
Go to the dataset you wish to examine, and click on the Lineage tab. For more details on how to use lineage on a dataset, see here.
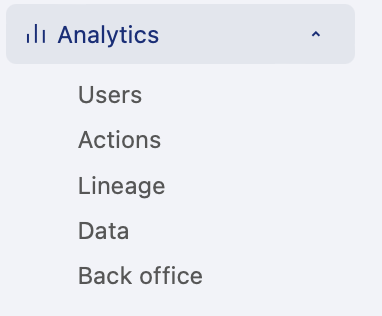
Go to the Analytics menu in the sidebar and click on "Lineage." For more details on how to use the lineage dashboard, see here.
A few key concepts and vocabulary
Many Opendatasoft clients have veritable data ecosystems. Data lineage provides a view of where your data comes from and is being used. But to do this, it uses a few key concepts it will help to understand: Broadly, what are the fundamental pieces of your ecosystem, and especially how do they relate to each other?
Objects and relationships
An ODS object is a dataset, a page, or else a map or chart created with a map or chart builder. A third-party object refers to an external source (file, URL, or remote service) of a dataset. These are the various pieces of your data ecosystem.
A relationship refers to how two objects are linked to each other, where one is the origin and the other is the destination.
In this example, A is the origin object and B the destination object. B depends on A.

These relationships can be direct or indirect, as described below.
A direct relationship
A direct relationship is one in which two objects are linked without any transformation. One is identified as the origin and the other as the destination.
In this example, dataset A is the origin object and dataset B is the destination object.

An indirect relationship
An indirect relationship occurs when a destination ODS object depends on a chain of direct or indirect relationships with other objects.
In this example, Dataset E is the origin of dataset A. In turn, Dataset A is the origin of Dataset B. Datasets E and B therefore have an indirect relationship.

An invalid relationship
A relationship is invalid when the origin object is no longer available within the Opendatasoft ecosystem. This can occur due to the deletion of the dataset, the removal or unpublishing of the workspace, or the unavailability of the dataset's source.
Upstream and downstream relationships
An ODS object has an upstream relationship if it is the destination object of another object and uses other objects for its construction. An object has a downstream relationship if it is used by other objects.
In the example below, Dataset E is upstream from Dataset A. Page P is downstream from Dataset A.

Specific relationship types
These are the different types of relationships that are possible between objects:
Uses a federation (public or private federation, federation by harvester, or federation by distribution)
Has a file, URL or remote service as a source
Is the result of a simple join (using the Join datasets processor) or a provided join (achieved using geographical processors)
Is used on pages, in the Studio, or in the map and chart builders
Reuses are not included in a data lineage.
Invalidity
A relationship can be considered invalid within the Opendatasoft ecosystem for several reasons, including:
Deletion, unpublishing or inaccessible: When the original ODS object is deleted or unpublished or when a third-party object becomes inaccessible, it disrupts the relationship and renders it invalid.
Workspace dissolution: If the workspace associated with the relationship no longer exists, the relationship becomes invalid, as the environment where the data was structured is no longer available.
Linked field alterations: Changes in linked fields such as deletion, renaming, or updates in their type can also invalidate relationships, as the reference points or connections are altered or are no longer accessible.
Declared and incognito modes
For the data lineage feature to be able to visualize the relationships between different objects, it's necessary to share usage metadata with other clients who own workspaces.
We want our clients to fully understand what data of theirs is collected and where it's being used. And notably, if their organization has special confidentiality requirements, to be able to opt-out of sharing the names of their workspaces.
Need more information about our collecting process? Detailed information is available here.
Sharing modes are available to prevent sharing the identity of the destination ODS object with the owners of the origin objects.
Two modes are available:
Declared mode
This is the default mode. Everyone will see the workspace name and the type of the destination object, but only authenticated users with relevant permissions will be able to see the name of the destination object. We encourage this mode because it gives other users the highest visibility on their data usage. In the lineage tab, you will see a locked icon on the ODS objects if you don’t have permissions.Incognito mode
This is the restricted mode for lineage, where the name of the workspace, and the type and the name of the destination object are hidden from other users. Only the information about the type of the relationship will be shared with the relevant workspaces. This mode is indicated with a incognito icon.
Usage between primary and secondary workspaces are automatically in declared mode. However, note that primary and secondary workspaces are considered independent for Lineage purposes. They will have no particular relationship to each other when sharing usage metadata. By default, a secondary workspace is assigned the sharing mode of its primary workspace, but this can be overridden.
Declared mode
This is the default mode. The relationship type, the title or name of the destination workspace are shared.
Other information is shared only if the user has the necessary permissions for the destination object:
The user doesn't have the necessary permissions
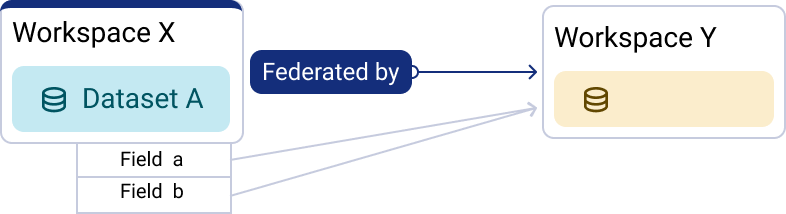
In this case, the Opendatasoft object has restricted access, and the user does not have the specific permissions to see it. The user can see the title or name of the destination workspace and the type of the destination object, but not its identity.
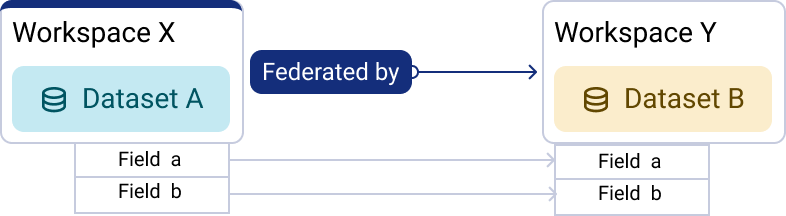
The ODS object is public, or else the user does have the necessary permissions
In this case, the ODS object has public access, or else has restricted access but the user does have the specifc permissions or role necessary to view it (they can view a dataset or page, browse all datasets, view all pages, browse statistics). In this case the user can also see the identifier, title and the linked fields of the destination object.
Third-party objects and their relationships are only visible on ODS objects that belong to the current workspace and according to the user's access conditions. They will not be transmitted to other workspaces that use the ODS object.
Incognito mode
This is the minimum level of information required to provide a lineage for ODS objects. By default and for each relationship, its type and information about the nature of the destination ODS object are shared with the origin workspace. Third-party objects are not affected and are not visible.
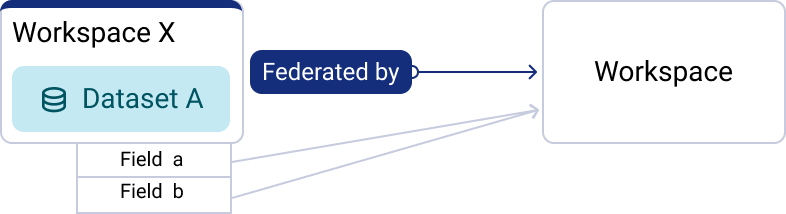
A summary of what is shared in each mode
Incognito mode | Declared mode (default) | |
Relation type | ✅ | ✅ |
ODS object type | ❌ | ✅ |
Name or title of the workspace | ❌ | ✅ |
Identifier or title of the ODS object | ❌ | Depends on the user's access. |
Linked fields of the ODS object | ❌ | Depends on the user's access. |
Third-party object | ❌ | Depends on the user's access. Not transmitted outside the current workspace. |