
Databricks connector
This connector is not available by default. Please contact Opendatasoft for the activation of this connector on a given Opendatasoft domain.
This article assumes you know the basics about how to use Databricks. If you do not, please refer to Databricks' documentation.
This connector allows you to use SQL to query your Databricks instance through either a SQL Warehouse or a Cluster.
To configure the Databricks connector, you will first need to obtain information found in Databricks. This will be on the configuration panel of either the warehouse or the cluster, depending on which you intend to connect to. With that information in hand, you can complete the connector's configuration.
Connector fields
Here are the fields of the connector configuration:
Field name | Required/optional |
Host | Required |
Port | Required |
HTTP path | Required |
Personal access token | Required |
Catalog | Required |
Schema | Optional |
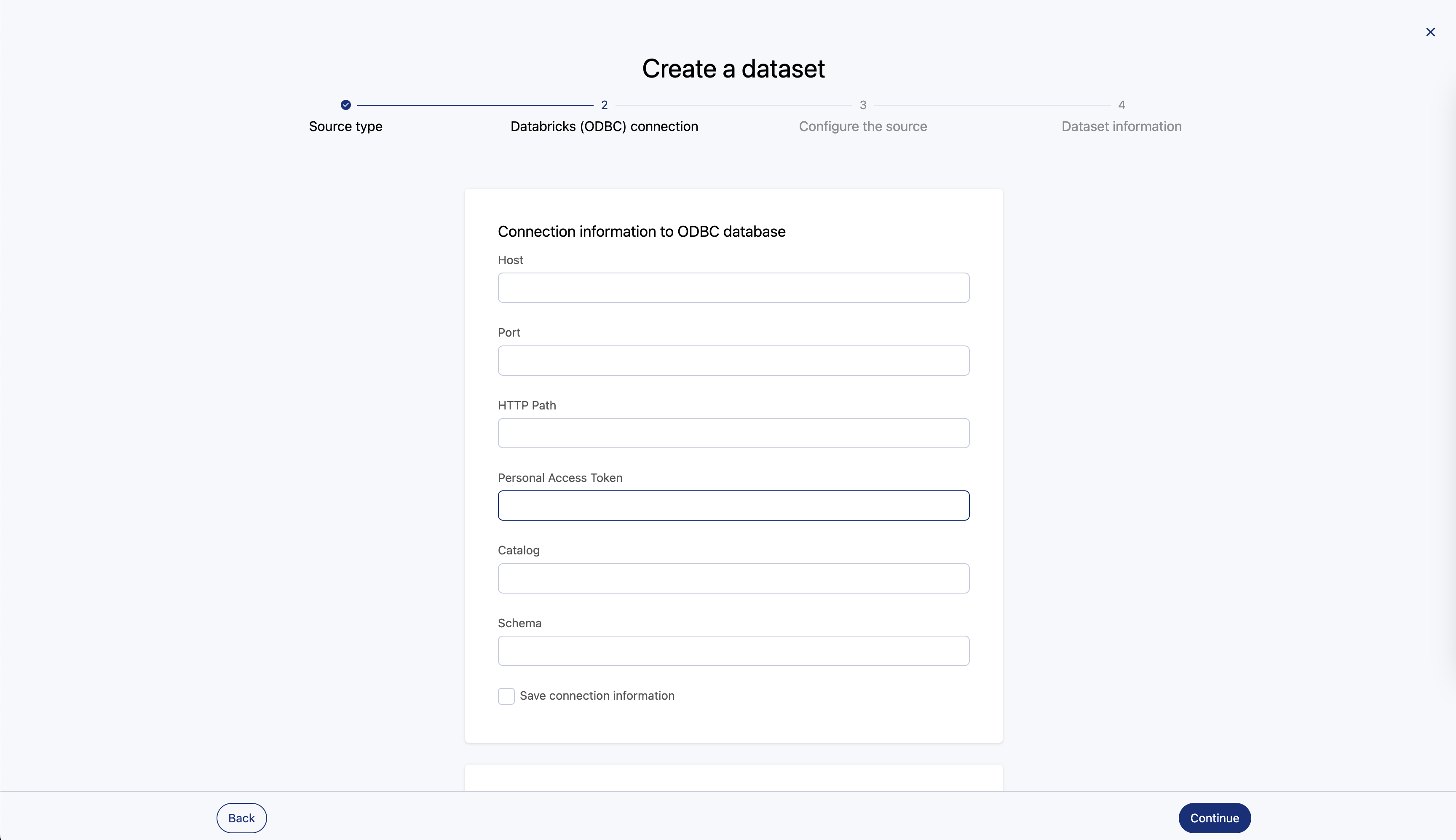
Follow these steps to connect your data portal to Databricks:
Connect to a Databricks warehouse
Below the first two steps are about gathering information necessary for Opendatasoft to connect to Databricks. The final two steps are about defining the data you want to query.
1. Retrieve Host, Port and HTTP path fields
Go to your Databricks Warehouse Connection details tab:
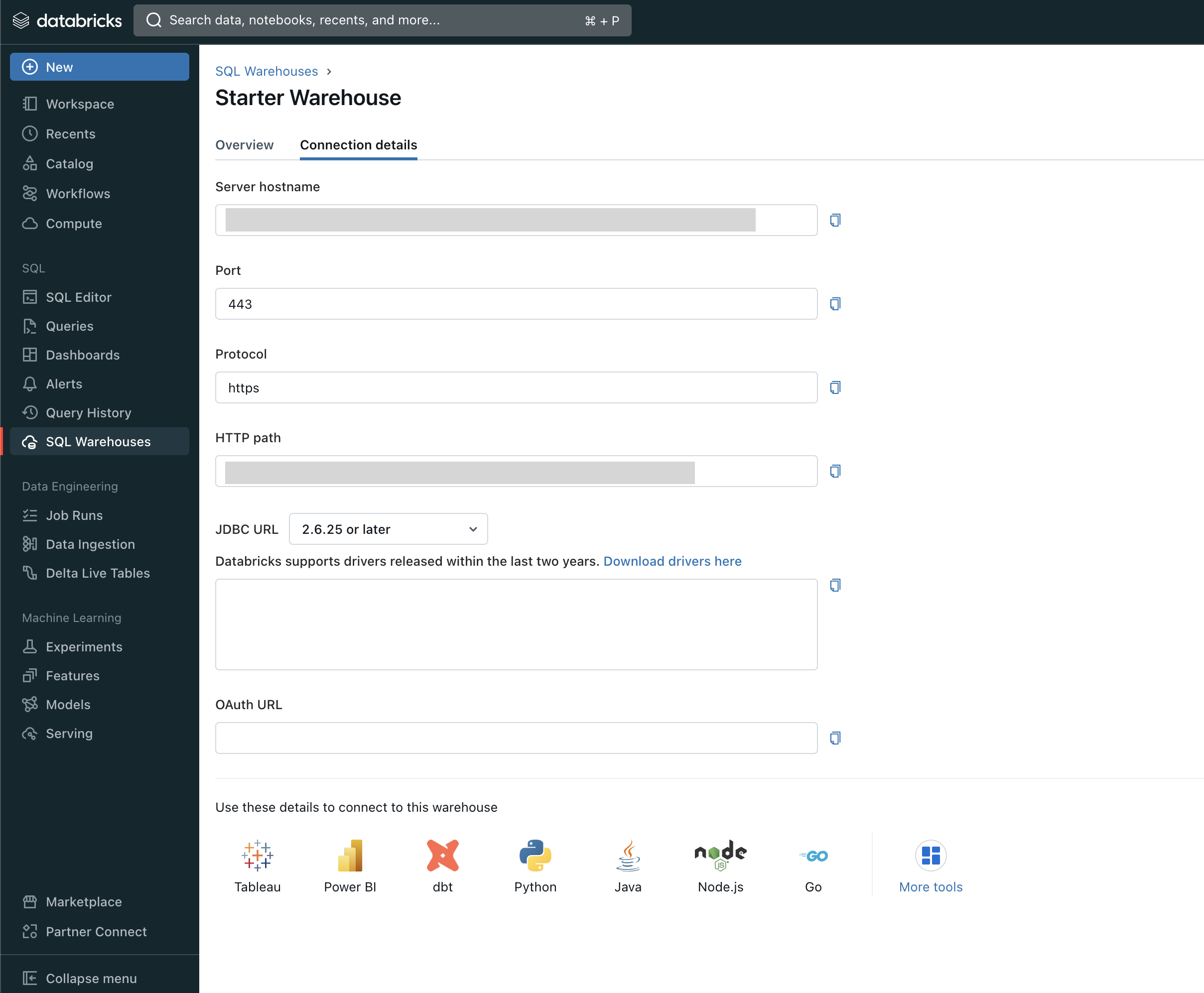
There, you need to copy the following:
Host
Port (443 by default)
HTTP path
2. Retrieve a personal access token
To allow Opendatasoft to communicate with your Databricks SQL warehouse, you need to provide a working personal access token. It can be created directly on the Databricks workspace.
3. Retrieve catalog and schema names
To find the catalog and schema, go to the Catalog Explorer page (click Catalog in the sidebar) and open the catalog you want to query.
4. Make the SQL query
You need to fill in the query fields using the catalog and schema names. Here is documentation that discusses each of those fields.
If you have decided not to specify the schema in the configuration, you will need to add it to the SQL query itself.For instance, if I chose to use the samples catalog but I did not specify that I wanted to use its nyctaxi schema to query the trips table, the query would look like: SELECT * FROM nyctaxi.trips
(Optional) Connect to a Cluster
You need to have either a Personal Compute Cluster or a Shared one.
If you go to your Cluster's configuration page > Advanced option > JDBC/ODBC, you'll see all the connection details you need to use to connect to this specific cluster.
You can use those and follow the same steps as the instructions above.