
Refining text searches within a dataset's records
When your users perform a text search in one of your datasets, you want to make sure it returns the most relevant results.
The "Records text search" feature allows you to control the relative importance of each of your dataset's fields is in any search results. And you can outright exclude fields that may be worth having in the data, but that might muddy any search results.
Configuring the feature
In your dataset, click on the Visualizations tab and look under “Records text search.”
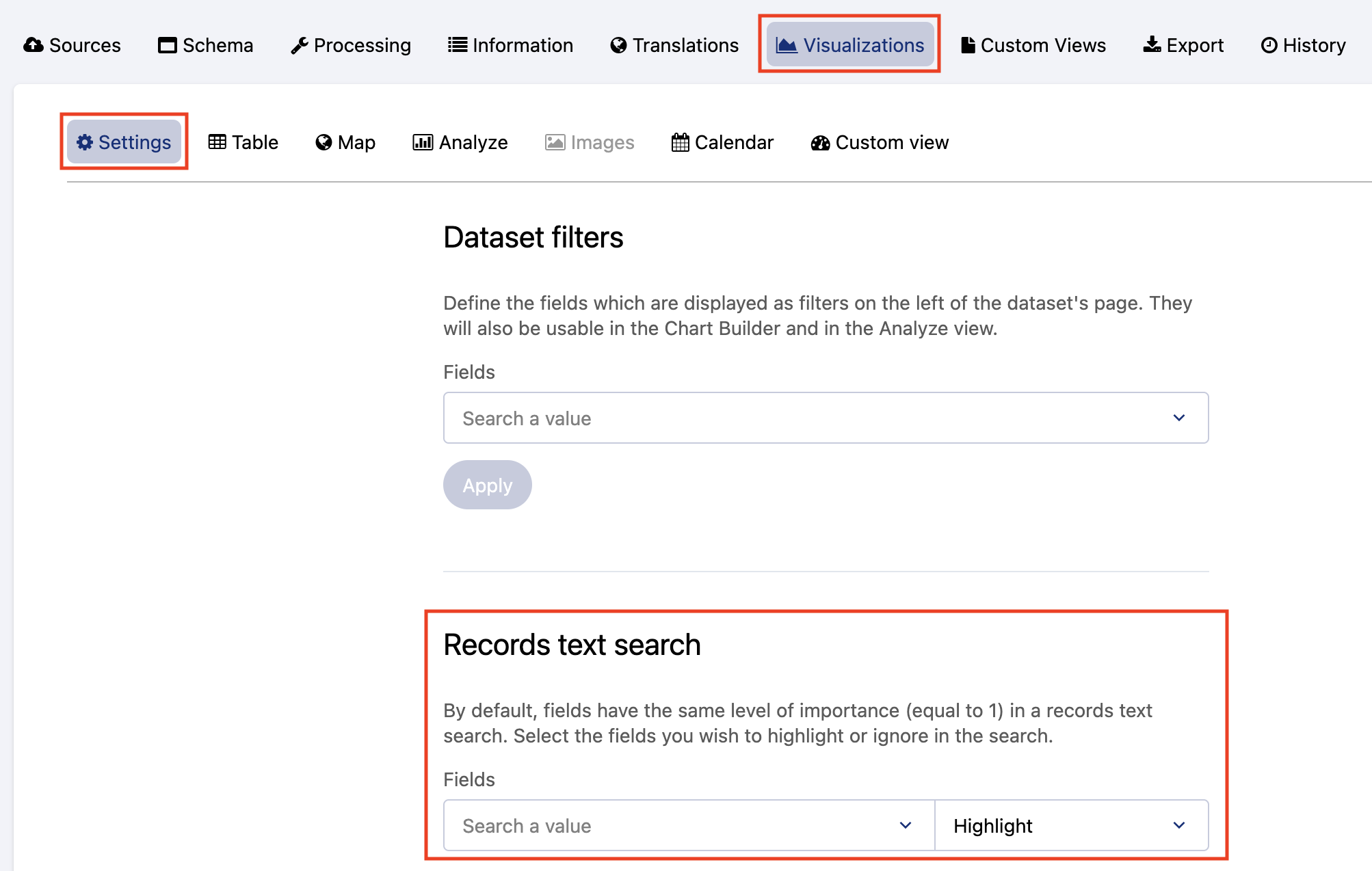
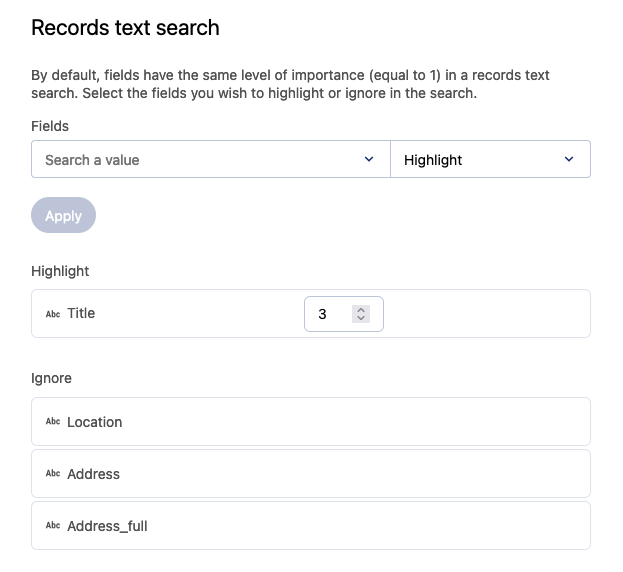
There you’ll see two dropdown menus: The first allows you to select the fields you want to modify, and the second allows you to choose if you want to highlight or hide them. Once you’ve made your selection, click Apply.
For fields you’ve chosen to highlight, you can adjust the weighting applied in users’ searches. The default value is 1, so any new value will be 2 or higher. Type in the number you wish, or click the up or down arrows.
And that’s it! You now have fine control over the search experience you want your users to have.
An example
To help you understand why this might sometimes come in handy, let’s imagine an example with data about films, with their titles, directors, where they were shot or are set, etc. If we imagine that the title is the main field, and the one we know users are looking for, we might weight the title higher, but also even exclude other fields, such as the location or address. This way, a search for “Paris, Texas” will show the film above all, and a search for “451” will bring up “Fahrenheit 451” and not an address.
Leveraging field types to improve search results
Though you should always type your fields as carefully as possible, remember that doing so is important for the quality of your search results.
See here for the full list of field types and their configurations.