
Connecteur Databricks
Ce connecteur n'est pas disponible par défaut. Merci de contacter Opendatasoft pour l'activation de ce connecteur sur votre espace de travail Opendatasoft.
Cet article suppose que vous connaissez les bases de l’utilisation de Databricks. Si ce n'est pas le cas, veuillez vous référer à la documentation de Databricks.
Ce connecteur vous permet d'utiliser SQL pour interroger votre instance Databricks via un SQL Warehouse ou un Cluster.
Pour configurer le connecteur Databricks, vous devrez d'abord obtenir les informations trouvées dans Databricks. Ce sera sur le panneau de configuration de l'entrepôt ou du cluster, selon celui auquel vous avez l'intention de vous connecter. Avec ces informations en main, vous pouvez terminer la configuration du connecteur.
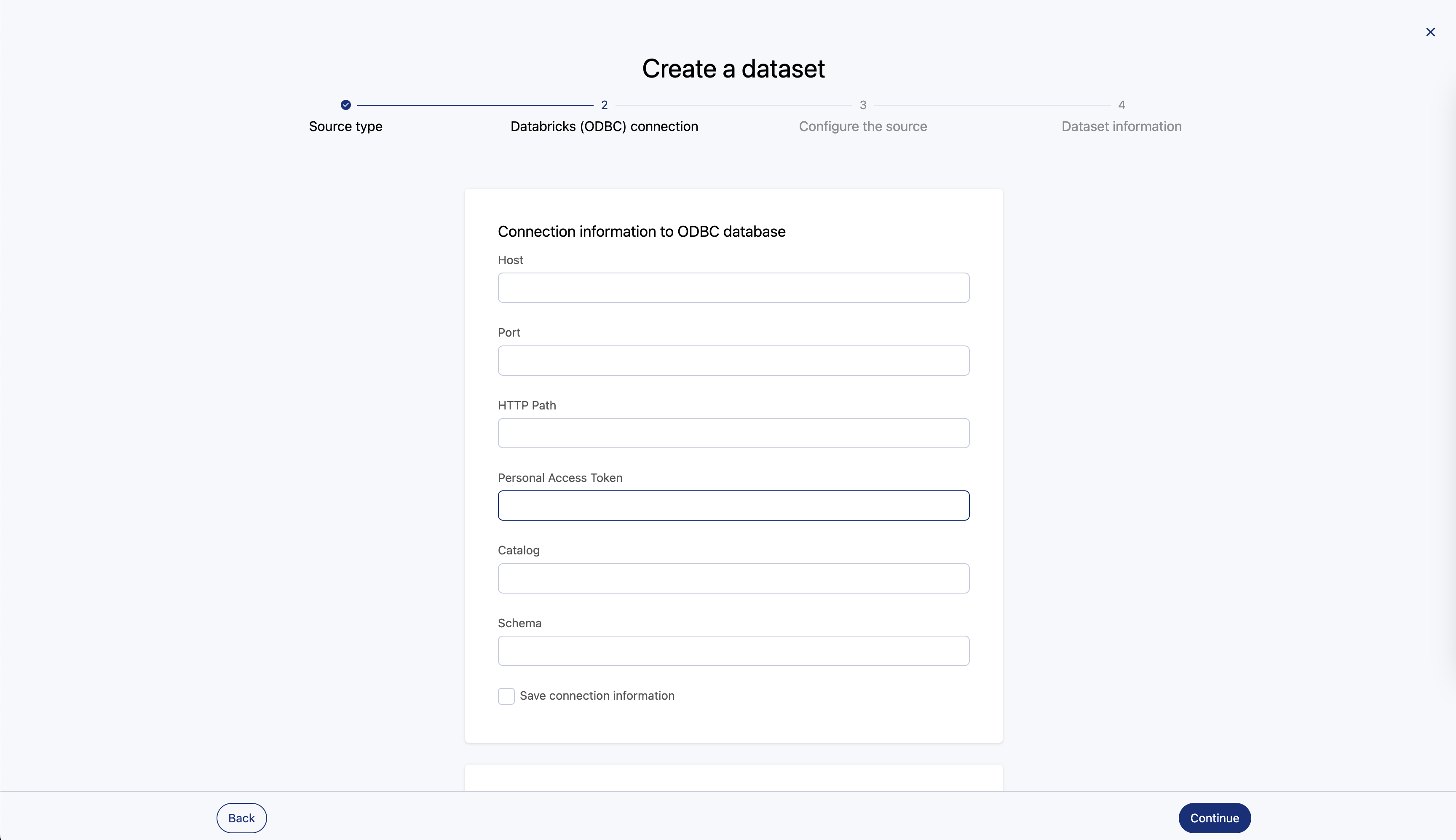
Champs de connecteur
Voici les champs de configuration du connecteur :
Nom de domaine | Obligatoire/facultatif |
Hôte | Requis |
Port | Requis |
HTTP path | Requis |
Personal access token | Requis |
Catalogue | Requis |
Schéma | Facultatif |
Suivez ces étapes pour connecter votre portail de données à Databricks :
Connectez-vous à un warehouse Databricks
Les deux premières étapes ci-dessous concernent la collecte des informations nécessaires à la connexion d'Opendatasoft à Databricks. Les deux dernières étapes consistent à définir les données que vous souhaitez interroger.
1. Récupérer les champs Hôte, Port et Chemin HTTP
Accédez à l’onglet Détails de votre connexion Databricks Warehouse :
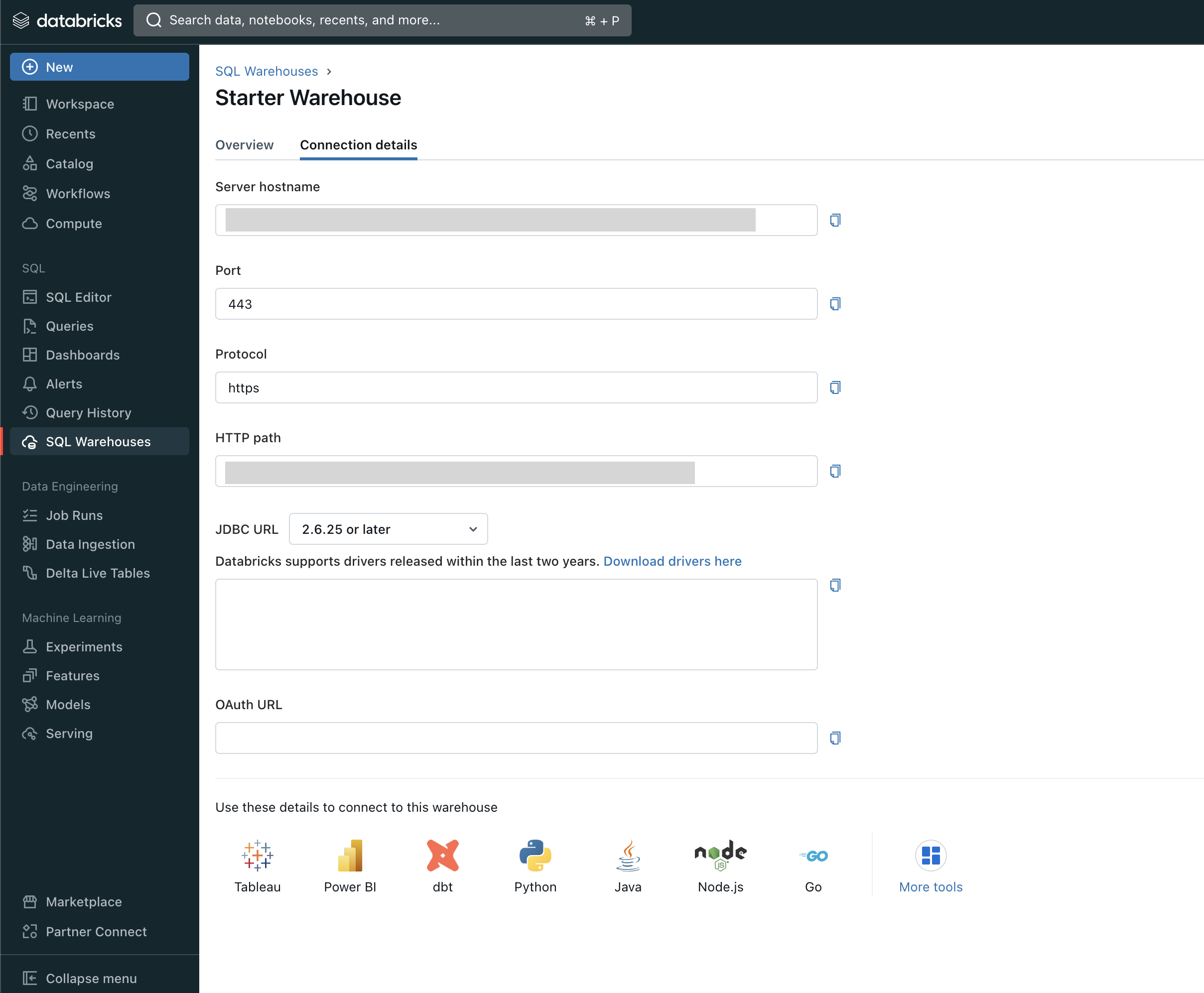
Là, vous devez copier ce qui suit :
Hôte
Port (443 par défaut)
HTTP path
2. Récupérer un personal access token
Pour permettre à Opendatasoft de communiquer avec votre SQL warehouse Databricks, vous devez fournir un personal access token fonctionnel. Il peut être créé directement sur l'espace de travail Databricks.
3. Récupérer les noms de catalogue et de schéma
Pour rechercher le catalogue et le schéma, accédez à la page Catalog Explorer (cliquez sur Catalog dans la barre latérale) et ouvrez le catalogue que vous souhaitez interroger.
4. Effectuez la requête SQL
Vous devez remplir les champs de requête en utilisant les noms de catalogue et de schéma. Voici la documentation qui traite de chacun de ces champs.
Si vous avez décidé de ne pas spécifier le schéma dans la configuration, vous devrez l'ajouter à la requête SQL elle-même. Par exemple, si j'ai choisi d'utiliser le catalogue samples mais que je n'ai pas précisé que je souhaitais utiliser son schéma nyctaxi pour requêter la table trips, la requête ressemblerait à : SELECT * FROM nyctaxi.trips
(Facultatif) Se connecter à un cluster
Vous devez disposer d'un cluster de calcul personnel ou partagé.
Si vous accédez à la page de configuration de votre cluster > Option avancée > JDBC/ODBC, vous verrez tous les détails de connexion que vous devez utiliser pour vous connecter à ce cluster spécifique.
Vous pouvez les utiliser et suivre les mêmes étapes que les instructions ci-dessus.