
Harvesting a catalog
Harvesters provide a way for administrators to easily create and update an important number of assets by importing them from an external source such as a CSW catalog or an ArcGIS service, among many others.
The two main usages of harvesters are:
Bootstrap your portal with assets from an existing portal
Keep your assets synchronized with an external service
The harvester will create assets, update their metadata and resources, keep them synchronized, and publish them.

Creating a harvester
To get started with harvesters, click on the harvesters menu in your back office and then on Add harvester. You will be asked to choose the type of portal you want to harvest, and a name for your harvester.
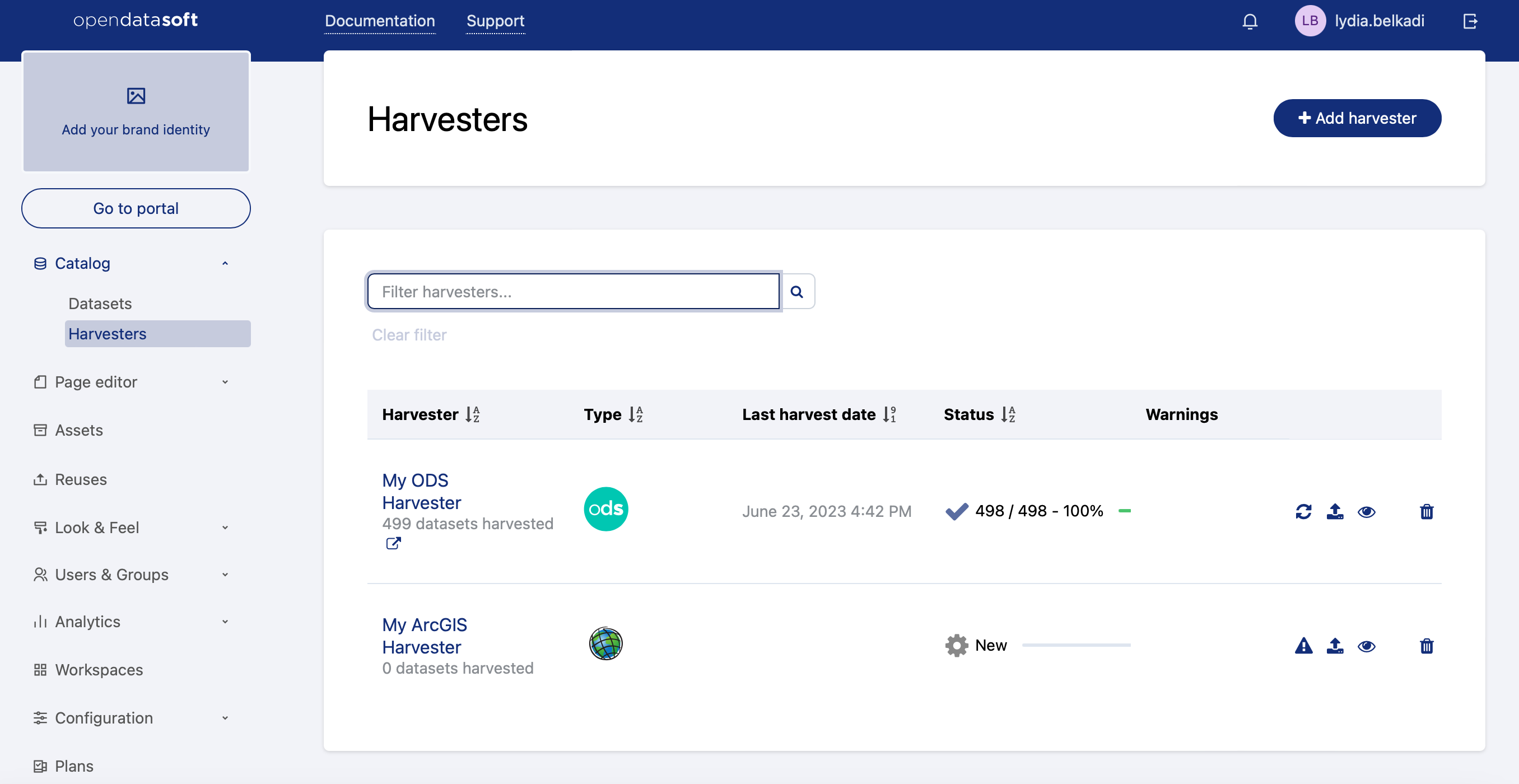
When you are done, click on Create harvester. You will be redirected to the configuration form of the harvester. As it depends on the harvester type, please refer to each harvester page below for detailed instructions.
Important: You must publish the assets for them to be visible on your portal. You can do this via the harvester button or via the assets.
Some options are available for every harvester type, such as:
Update on deletion: if the source assets are deleted on the harvested portal, delete them on this Opendatasoft portal too. Otherwise, you may have assets that are not available on the external service anymore (e.g: if they are deleted from the external service).
Download resources: download resources instead of attaching them via URL. This option allows you to detach your assets from the remote portal by permanently copying all required data on the Opendatasoft platform. Otherwise, your assets will be linked to the external service and will access remote asseets via their URL for every publishing.
Restrict visibility: make the visibility of harvested assets restricted. Otherwise, they will have the default visibility of your portal.
Default metadata, inspire metadata, DCAT metadata: allow you to override some metadata in every harvested asset. Useful if you want to force the theme or publisher instead of using the one used on the external service.
Once you are done configuring the harvester, you can click on the Preview button to test run it on a few assets. If you see some titles and descriptions and they look correct, you are all set. Otherwise, please double check your configuration.
Running a harvester
The harvesting process can be quite long on external services with many assets or with big ones. That's why it's split into two phases:
First, the harvester will connect to the remote service and discover all the assets it contains. It will then create an unpublished asset for each remote asset it finds. These assets will contain all available metadata and resources (as URLs or as files depending on the download resources option). This happens when you click on the Start harvester button.
Next, it will process and publish all the harvested assets. This step can take a while. This happens when you click on the Publish button.
Editing harvested assets
Before publishing them, you can change the metadata of the harvested assets by overriding the initial metadata value. This override will be kept even if you restart your harvester.
Deleting a harvester
When you delete a harvester by clicking the Delete harvester button, you can choose between keeping the harvested assets (they will be kept as regular assets in your catalog) or by deleting them with the harvester.
If you choose to keep them, please keep in mind that you will have to handle them one by one to unpublish or delete them afterward and that they will be duplicated if you recreate another harvester on the same external service.
Harvester types
Portals
Opendatasoft Federation harvester, data.gouv.fr harvester, ArcGIS harvester, ArcGIS Hub Portals harvester, CKAN harvester, Socrata harvester, data.json harvester, Quandl harvester
Services
CSW harvester, FTP with meta CSV harvester
Unless otherwise specified, all harvesters use HTTPS by default but support HTTP if specified in the provided URL.The FTP harvester uses FTPS (explicit mode on port 21) by default but supports FTP if specified in the provided URL or if the remote server does not support FTPS.
Scheduling
From the configuration page of a harvester, it is possible to make it run periodically. To do this, scroll to the bottom of the page and click on Set recurring runs. You can run the harvester every day or choose the days of the week or the days of the month it will run on. However, you always have to choose the time of day when it will run because it can not run more than once a day.
The periodic run will only trigger if the harvester has been run at least once.
At the end of a scheduled run, all the harvester's already published assets will be republished, but unpublished assets or new assets will not be automatically published.
