
Publishing data in JSON format
JSON is an open-standard format that uses human-readable text to transmit data objects consisting of key-value pairs. It is the most common data format to build web APIs.
As JSON documents can have a lot of different forms, the platform can extract data from JSON files, JSON Lines files, and JSON dictionaries.
If the platform does not fully extract a document with a complex structure, use one of the JSON processors to complete the extraction.
JSON File
You can use a JSON file as a source. From this file, the platform extracts a valid JSON document (array or object) into one dataset of several records:
If the document is a JSON array, a record will be created for each object inside the array (the keys will be used as column names).
If the document is a JSON object, the "JSON root" parameter should contain a dot-separated path to the array inside your object. If not provided, the platform tries
items.
For each item inside the array, the platform can follow another path before extracting the records with the parameter "JSON object".
Supported field types
Regular fields (decimal, boolean, string)
JSON object: used as-is
Array:
If the array contains JSON objects, it is used as-is.
If the array contains strings, a multivalued field is created with all the strings separated by a semicolon (
;).
Configuration
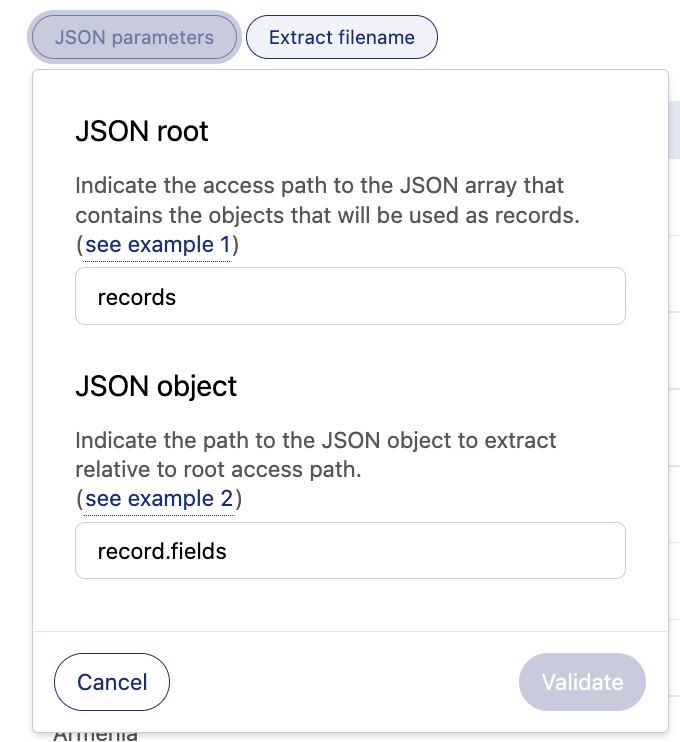
JSON root
JSON root indicates the path to the JSON array that contains the objects to be extracted as the future records of your dataset.
If the JSON array that contains the future data is at the root of the document, leave the JSON root box empty. If the JSON file is a JSON object, enter the ijson path to the array in the JSON root box.
Note that ijson is a syntax to navigate inside JSON objects, consisting of separating attribute names with dots.
JSON object
In the JSON object box, indicate the relative path to the JSON object to extract.
Examples
1. In this first example, the JSON array is located at the root of the file. The JSON root box must therefore be left empty.
[
{
"name": "Agra Express",
"origin": "Agra Cantt",
"destination": "New Delhi"
},
{
"name": "Gour Express",
"origin": "Balurghat",
"destination": "Sealdah"
}
]And the resulting dataset will have this schema:
name | origin | destination |
Agra Express | Agra Cantt | New Delhi |
Gour Express | Balurghat | Sealdah |
2. In this second example, the JSON file is more complex. The correct JSON root to put is content.trains.
{
"filename": "trains.json",
"content": {
"trains": [
{
"id": 123,
"info": {
"name": "Agra Express",
"origin": "Agra Cantt",
"destination": "New Delhi"
}
},
{
"id": 555,
"info": {
"name": "Gour Express",
"origin": "Balurghat",
"destination": "Sealdah"
}
}
]
}
}
If content.trains is set as the JSON root, the resulting dataset will be:
id | info |
123 | {"origin": "Agra Cantt", "destination": "New Delhi", "name": "Agra Express"} |
555 | {"origin": "Balurghat", "destination": "Sealdah", "name": "Gour Express"} |
To only extract the info JSON objects, and skip the id number, you should put the info object as JSON root. Only then, the resulting dataset will be:
name | origin | destination |
Agra Express | Agra Cantt | New Delhi |
Gour Express | Balurghat | Sealdah |