 Getting started
Getting started
 Exploring and using data
Exploring and using data
Exploring catalogs and datasets
Exploring a catalog of datasets
What's in a dataset
Filtering data within a dataset
An introduction to the Explore API
An introduction to the Automation API
Introduction to the WFS API
Downloading a dataset
Search your data with AI (vector search)
Creating maps and charts
Creating advanced charts with the Charts tool
Overview of the Maps interface
Configure your map
Manage your maps
Reorder and group layers in a map
Creating multi-layer maps
Share your map
Navigating maps made with the Maps interface
Rename and save a map
Creating pages with the Code editor
How to limit who can see your visualizations
Archiving a page
Managing a page's security
Creating a page with the Code editor
Content pages: ideas, tips & resources
How to insert internal links on a page or create a table of contents
Sharing and embedding a content page
How to troubleshoot maps that are not loading correctly
Creating content with Studio
Creating content with Studio
Adding a page
Publishing a page
Editing the page layout
Configuring blocks
Previewing a page
Adding text
Adding a chart
Adding an image block to a Studio page
Adding a map block in Studio
Adding a choropleth map block in Studio
Adding a points of interest map block in Studio
Adding a key performance indicator (KPI)
Configuring page information
Using filters to enhance your pages
Refining data
Managing page access
How to edit the url of a Studio page
Embedding a Studio page in a CMS
Visualizations
Managing saved visualizations
Configuring the calendar visualization
The basics of dataset visualizations
Configuring the images visualization
Configuring the custom view
Configuring the table visualization
Configuring the map visualization
Understanding automatic clustering in maps
Configuring the analyze visualization
 Publishing data
Publishing data
Publishing datasets
Creating a dataset
Creating a dataset from a local file
Creating a dataset with multiple files
Creating a dataset from a remote source (URL, API, FTP)
Creating a dataset using dedicated connectors
Creating a dataset with media files
Federating an Opendatasoft dataset
Publishing a dataset
Publishing data from a CSV file
Publishing data in JSON format
Supported file formats
Promote mobility data thanks to GTFS and other formats
What is updated when publishing a remote file?
Configuring datasets
Automated removal of records
Configuring dataset export
Checking dataset history
Configuring the tooltip
Dataset actions and statuses
Dataset limits
Defining a dataset schema
How Opendatasoft manages dates
How and where Opendatasoft handles timezones
How to find your workspace's IP address
Keeping data up to date
Processing data
Translating a dataset
How to configure an HTTP connection to the France Travail API
Deciding what license is best for your dataset
Types of source files
OpenStreetMap files
Shapefiles
JSON files
XML files
Spreadsheet files
RDF files
CSV files
MapInfo files
GeoJSON files
KML/KMZ files
GeoPackage
Connectors
Saving and sharing connections
Airtable connector
Amazon S3 connector
ArcGIS connector
Azure Blob storage connector
Database connectors
Dataset of datasets (workspace) connector
Eco Counter connector
Feed connector
Google BigQuery connector
Google Drive connector
How to find the Open Agenda API Key and the Open Agenda URL
JCDecaux connector
Netatmo connector
OpenAgenda connector
Realtime connector
Salesforce connector
SharePoint connector
U.S. Census connector
WFS connector
Databricks connector
Connecteur Waze
Harvesting a catalog
ArcGIS harvester
ArcGIS Hub Portals harvester
CKAN harvester
CSW harvester
FTP with meta CSV harvester
Opendatasoft Federation harvester
Quandl harvester
Socrata harvester
data.gouv.fr harvester
data.json harvester
Processors
What is a processor and how to use one
Add a field processor
Compute geo distance processor
Concatenate text processor
Convert degrees processor
Copy a field processor
Correct geo shape processor
Create geo point processor
Decode HTML entities processor
Decode a Google polyline processor
Deduplicate multivalued fields processor
Delete record processor
Expand JSON array processor
Expand multivalued field processor
Expression processor
Extract HTML processor
Extract URLs processor
Extract bit range processor
Extract from JSON processor
Extract text processor
File processor
GeoHash to GeoJSON processor
GeoJoin processor
Geocode with ArcGIS processor
Geocode with BAN processor (France)
Geocode with PDOK processor
Geocode with the Census Bureau processor (United States)
Geomasking processor
Get coordinates from a three-word address processor
IP address to geo Coordinates processor
JSON array to multivalued processor
Join datasets processor
Meta expression processor
Nominatim geocoder processor
Normalize Projection Reference processor
Normalize URL processor
Normalize Unicode values processor
Normalize date processor
Polygon filtering processor
Replace text processor
Replace via regular expression processor
Retrieve Administrative Divisions processor
Set timezone processor
Simplify Geo Shape processor
Skip records processor
Split text processor
Transform boolean columns to multivalued field processor
Transpose columns to rows processor
WKT and WKB to GeoJson processor
what3words processor
Data Collection Form
About the Data Collection Form feature
Data Collection Forms associated with your Opendatasoft workspace
Create and manage your data collection forms
Sharing and moderating your data collection forms
Dataset metadata
![]() Analyzing how your data is used
Analyzing how your data is used
Getting involved: Sharing, Reusing and Reacting
Discovering & submitting data reuses
Sharing through social networks
Commenting via Disqus
Submitting feedback
Following dataset updates
Sharing and embedding data visualizations
Monitoring usage
An overview of monitoring your workspaces
Analyzing user activity
Analyzing actions
Detail about specific fields in the ods-api-monitoring dataset
How to count a dataset's downloads over a specific period
Analyzing data usage
Analyzing a single dataset with its monitoring dashboard
Analyzing back office activity
Using the data lineage feature
 Managing your users
Managing your users
Managing limits
Managing users
Managing users
Setting quotas for individual users
Managing access requests
Inviting users to the portal
Managing workspaces
 Managing your portal
Managing your portal
Configuring your portal
Configure catalog and dataset pages
Configuring a shared catalog
Sharing, reusing, communicating
Customizing your workspace's URL
Managing legal information
Connect Google Analytics (GA4)
Regional settings
Pictograms reference
Managing tracking
Look & Feel
Branding your portal
Customizing portal themes
How to customize my portal according to the current language
Managing the dataset themes
Configuring data visualizations
Configuring the navigation
Adding IGN basemaps
Adding assets
Plans and quotas
Managing security
Configuring your portal's overall security policies
A dataset's Security tab
Mapping your directory to groups in Opendatasoft (with SSO)
Single sign-on with OpenID Connect
Single sign-on with SAML
Parameters
FTP with meta CSV harvester

This harvester allows you to create datasets from an FTP folder.
It connects via FTPS (explicit mode on port 21) if available, or FTP if requested in the provided URL.
The FTP folder must contain:
- One metadata CSV file (separated with semicolons)
- Several resources
- (Optional) several CSV schema files
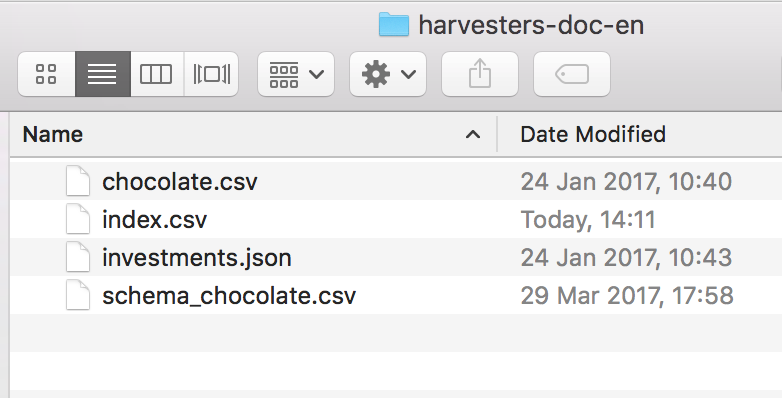
Metadata CSV file
The metadata CSV file is a semicolon-separated file which contains:
- One header row
- Several other rows, each one dedicated to a dataset to harvest
Example:
name;title;description;theme;keyword;source_dataset;schema_file
Row ID 1;Chocolate bars database;"A database of chocolate bars";Health;Chocolate;chocolate.csv;schema_chocolate.csv
Row ID 2;Venture Capital Investments;Venture capital industry statistics.;Economy, Business;"Venture capital;Investments;IPO;Acquisitions";investments.json;
name | title | description | theme | keyword | source_dataset | schema_file |
Row ID 1 | Chocolate bars database | A database of chocolate bars | Health | Chocolate | chocolate.csv | schema_chocolate.csv |
Row ID 2 | Venture Capital Investments | Venture capital industry statistics. | Economy, Business | Venture capital;Investments;IPO;Acquisitions | investments.json |
|
- The
namecolumn must contain a unique identifier for each row.Note that thenamedoes not define the technical IDs for the harvested datasets, which are produced automatically by the platform based on thetitle, ornameif the title is not defined. - The CSV resource column (
source_datasetby default) contains the resource for each row. - The optional CSV schema column (here,
schema_file) contains the schema file for each row. - Every other column is a piece of metadata (see the table below for the complete list of accepted column names).
keyword, where you have to use semicolons to separate words (e.g "keyword1;keyword2").Accepted metadata columns
Template | Column name |
Standard |
Note that the techincal |
Custom |
For example, if the metadata name is "project name", use This template is used in cases where your CSV contains custom fields. For these fields to be taken into account, you must create a template with the template id "custom" to store those fields. Please contact our support for further information. |
DCAT (if activated) |
|
DCAT-AP for CH (if activated) |
|
Inspire (if activated) |
|
Semantic (if activated) |
|
For more information about the standard metadata, see this page.
The geographic_reference_auto metadata
The geographic_reference_auto column defines whether the dataset's geographic coverage is automatically computed and accepts a Boolean value:
Value | Purpose |
| Sets the Geographic coverage metadata for the dataset to Automatic. The geographic coverage is automatically computed based on the dataset content or on the domain's dataset default geographic coverage. |
| Sets the Geographic coverage metadata for the dataset to the value for |
The geographic_reference metadata
The geographic_reference column defines the location used for the dataset geographic coverage, which means the Geographic coverage metadata for the dataset is set to Specific. This geographic_reference column contains an array of georeference unique identifiers representing locations.
Georeference unique identifiers use the following syntaxes based on the reference:
Reference | Description | Syntax | Example value |
world | The dataset contains content about different countries |
|
|
country | The dataset contains country-level content |
|
|
lower division | The dataset contains content about a specific country division |
|
|
{{country code}}is a two-letter country code defined in ISO 3166-1 alpha-2. For example,frfor France.{{administrative-level}}is an administrative level for the country. For example,40is the administrative level for French regions. For more information about the administrative levels available for the desired country, see here.{{administrative division}}is the relative administration division within the country's administrative level. For example,11is the code for the Île-de-France French region.
You can retrieve the desired administrative division code as follows:
- Go to the documentation.
- From the table at the end of the section, select a country and an administrative level.
- From the related table row, click the link in the Dataset URL column to open the related geographical referential and get the desired administrative division code.
Resources
Resources can either be:
- Files on the FTP server, in the same folder as the
index.csvfile, or under a subdirectory by specifying the relative path to the file in the column (e.g "resources/chocolate.csv") - Any URL pointing towards a supported format
If the column is empty, the dataset will contain only metadata.
Resources in any format supported by the platform can be harvested. However, as the harvester heavily relies on automatically detecting parameters for the connector's configuration, files must be simple enough to be correctly extracted.
Schema CSV file
For each resource, the FTP folder can contain a CSV schema file that defines labels and descriptions for each field of the dataset.
The file name of each schema file must be written in the CSV schema column. This file has the following specifications:
- A
namecolumn holds each field name in lowercase (e.g. on a CSV resource, this would be the column names in lowercase) - A
labelcolumn (optional) holds the label of the corresponding field - A
descriptioncolumn (optional) holds the description of the corresponding field
name;label;description
company;Company;The company that makes the bar
ref;Reference;The product id of the chocolate bar
Name | Label | Description |
company | Company | The company that makes the bar |
ref | Reference | The product id of the chocolate bar |
The schema files do not need to contain a row for each field, and it is not required to provide a schema file for each dataset in the index.csv. In the latter case, keep the corresponding cell empty.
Parameters
Name | Description | Example |
Host (host) | URL of the FTP server | eu.ftp.opendatasoft.com, ftps://eu.ftp.opendatasoft.com, ftp://eu.ftp.opendatasoft.com |
User (user) | Your username |
|
Password (password) | Your password |
|
Subdirectory (subdir) | The directory containing the data you want to harvest | pub/documents |
Metadata CSV filename (metadata_file) | The file holding the metadata and filenames (see above for more precise specifications) | index.csv |
Metadata CSV resource column (resource_location_column) | This column holds a filename or an URL with the dataset resource | source_dataset |
Metadata CSV schema column (resource_schema_column) | This column holds a filename with the resource schema (column labels and descriptions) |
|