 Getting started
Getting started
 Exploring and using data
Exploring and using data
Exploring catalogs and datasets
Exploring a catalog of datasets
What's in a dataset
Filtering data within a dataset
An introduction to the Explore API
An introduction to the Automation API
Introduction to the WFS API
Downloading a dataset
Search your data with AI (vector search)
The Explore data with AI feature
Creating maps and charts
Creating advanced charts with the Charts tool
Overview of the Maps interface
Configure your map
Manage your maps
Reorder and group layers in a map
Creating multi-layer maps
Share your map
Navigating maps made with the Maps interface
Rename and save a map
Creating pages with the Code editor
How to limit who can see your visualizations
Archiving a page
Managing a page's security
Creating a page with the Code editor
Content pages: ideas, tips & resources
How to insert internal links on a page or create a table of contents
Sharing and embedding a content page
How to troubleshoot maps that are not loading correctly
Creating content with Studio
Creating content with Studio
Adding a page
Publishing a page
Editing the page layout
Configuring blocks
Previewing a page
Adding text
Adding a chart
Adding an image block to a Studio page
Adding a map block in Studio
Adding a choropleth map block in Studio
Adding a points of interest map block in Studio
Adding a key performance indicator (KPI)
Configuring page information
Using filters to enhance your pages
Refining data
Managing page access
How to edit the url of a Studio page
Embedding a Studio page in a CMS
Visualizations
Managing saved visualizations
Configuring the calendar visualization
The basics of dataset visualizations
Configuring the images visualization
Configuring the custom view
Configuring the table visualization
Configuring the map visualization
Understanding automatic clustering in maps
Configuring the analyze visualization
 Publishing data
Publishing data
Publishing datasets
Creating a dataset
Creating a dataset from a local file
Creating a dataset with multiple files
Creating a dataset from a remote source (URL, API, FTP)
Creating a dataset using dedicated connectors
Creating a dataset with media files
Federating an Opendatasoft dataset
Publishing a dataset
Publishing data from a CSV file
Publishing data in JSON format
Supported file formats
Promote mobility data thanks to GTFS and other formats
What is updated when publishing a remote file?
Automated removal of records
Configuring dataset export
Checking dataset history
Configuring the tooltip
Dataset actions and statuses
Dataset limits
Defining a dataset schema
How Opendatasoft manages dates
How and where Opendatasoft handles timezones
How to find your workspace's IP address
Keeping data up to date
Processing data
Translating a dataset
How to configure an HTTP connection to the France Travail API
Deciding what license is best for your dataset
Types of source files
OpenStreetMap files
Shapefiles
JSON files
XML files
Spreadsheet files
RDF files
CSV files
MapInfo files
GeoJSON files
KML/KMZ files
GeoPackage
Connectors
Saving and sharing connections
Airtable connector
Amazon S3 connector
ArcGIS connector
Azure Blob storage connector
Database connectors
Dataset of datasets (workspace) connector
Eco Counter connector
Feed connector
Google BigQuery connector
Google Drive connector
How to find the Open Agenda API Key and the Open Agenda URL
JCDecaux connector
Netatmo connector
OpenAgenda connector
Realtime connector
Salesforce connector
SharePoint connector
U.S. Census connector
WFS connector
Databricks connector
Connecteur Waze
Harvesters
Harvesting a catalog
ArcGIS harvester
ArcGIS Hub Portals harvester
CKAN harvester
CSW harvester
FTP with meta CSV harvester
Opendatasoft Federation harvester
Quandl harvester
Socrata harvester
data.gouv.fr harvester
data.json harvester
Processors
What is a processor and how to use one
Add a field processor
Compute geo distance processor
Concatenate text processor
Convert degrees processor
Copy a field processor
Correct geo shape processor
Create geo point processor
Decode HTML entities processor
Decode a Google polyline processor
Deduplicate multivalued fields processor
Delete record processor
Expand JSON array processor
Expand multivalued field processor
Expression processor
Extract HTML processor
Extract URLs processor
Extract bit range processor
Extract from JSON processor
Extract text processor
File processor
GeoHash to GeoJSON processor
GeoJoin processor
Geocode with ArcGIS processor
Geocode with BAN processor (France)
Geocode with PDOK processor
Geocode with the Census Bureau processor (United States)
Geomasking processor
Get coordinates from a three-word address processor
IP address to geo Coordinates processor
JSON array to multivalued processor
Join datasets processor
Meta expression processor
Nominatim geocoder processor
Normalize Projection Reference processor
Normalize URL processor
Normalize Unicode values processor
Normalize date processor
Polygon filtering processor
Replace text processor
Replace via regular expression processor
Retrieve Administrative Divisions processor
Set timezone processor
Simplify Geo Shape processor
Skip records processor
Split text processor
Transform boolean columns to multivalued field processor
Transpose columns to rows processor
WKT and WKB to GeoJson processor
what3words processor
Data Collection Form
About the Data Collection Form feature
Data Collection Forms associated with your Opendatasoft workspace
Create and manage your data collection forms
Sharing and moderating your data collection forms
Dataset metadata
![]() Analyzing how your data is used
Analyzing how your data is used
Getting involved: Sharing, Reusing and Reacting
Discovering & submitting data reuses
Sharing through social networks
Commenting via Disqus
Submitting feedback
Following dataset updates
Sharing and embedding data visualizations
Monitoring usage
An overview of monitoring your workspaces
Analyzing user activity
Analyzing actions
Detail about specific fields in the ods-api-monitoring dataset
How to count a dataset's downloads over a specific period
Analyzing data usage
Analyzing a single dataset with its monitoring dashboard
Analyzing back office activity
Using the data lineage feature
 Managing your users
Managing your users
Managing limits
Managing users
Managing users
Setting quotas for individual users
Managing access requests
Inviting users to the portal
Managing workspaces
 Managing your portal
Managing your portal
Configuring your portal
Configure catalog and dataset pages
Configuring a shared catalog
Sharing, reusing, communicating
Customizing your workspace's URL
Managing legal information
Connect Google Analytics (GA4)
Regional settings
Pictograms reference
Managing tracking
Best practices for search engine optimization (SEO)
Look & Feel
Branding your portal
Customizing portal themes
How to customize my portal according to the current language
Managing the dataset themes
Configuring data visualizations
Configuring the navigation
Adding IGN basemaps
Adding images and fonts
Plans and quotas
Managing security
Configuring your portal's overall security policies
A dataset's Security tab
Mapping your directory to groups in Opendatasoft (with SSO)
Single sign-on with OpenID Connect
Single sign-on with SAML
Parameters
Keeping data up to date

- Using scheduling to keep a dataset up to date
- Adding a source
- Specifying scheduling interval
- Pushing realtime data
The Opendatasoft platform makes it possible to update the data within static datasets (which need to be published only once) and live datasets (which need to be regularly updated).
Two different mechanisms are available:
- Scheduling consists of having a dataset being automatically republished at fixed intervals. This mode is most useful for datasets with a remote resource that is regularly updated.
- Pushing realtime data on the Opendatasoft platform using a dedicated API endpoint. This mode is most useful when the data can be sent directly by the system that produces the data points, such as a computer program sending event metrics or a set of sensors sending their readings.
Using scheduling to keep a dataset up to date
Data in a dataset can be kept up to date by being automatically republished at fixed intervals. This is the easiest solution to implement. It does not require any coding, only a suitable source and some settings in the dataset configuration.
Note that scheduling updates only a dataset's data. Changes made to the configuration of your dataset will only be taken into account when you manually publish the dataset. This is by design, since datasets that are updated frequently—every minute is not unheard of—would offer you very little time to prepare whatever changes you wish to make to the configuration!
Adding a source
To schedule a dataset, you need to add a suitable source—a file via an FTP or HTTP address, or else a remote service. For more information, see Retrieving a file and Configuring a remote service.
Specifying scheduling interval
Once you saved a dataset with a remote source, the Scheduling tab is activated:
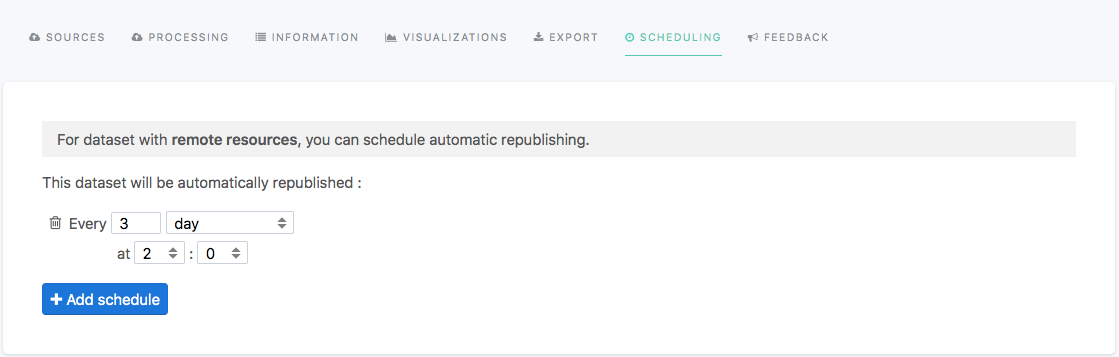
From this tab, you can add as many schedules as you want. For example, if it fits your needs, you could decide to schedule a dataset to be reprocessed every Monday morning and every Wednesday afternoon.
By default, the minimum scheduling interval is one day. Please contact Opendatasoft's support if you need minute-level scheduling in your workspace.
In standard time, this means schedules run on Central European Time (CET), or in other words GMT+1. In the summer months, schedules run on Central European Summer Time (CEST), or in other words GMT+2.
Note that in places that use Daylight Saving Time, countries can make the switch on different dates.
Pushing realtime data
For some types of data, it can be helpful to push data instead of the more traditional model of having the data being pulled from a resource by the platform. To address this need, the Opendatasoft platform offers a realtime push API.
It is not to be confused with the ability to schedule a dataset processing. When scheduling, the dataset will periodically pull the resource and process the data inside it. In contrast, with the push API, the dataset is fed by an application through a push API, and records are processed one by one as soon as they are received.
Configuring the dataset schema
- In Catalog > Datasets, click on the New dataset button.
- In the wizard that opens, select Realtime under the Configure a remote service section.
- In the Real time data schema box, enter some bootstrap data. The data should have all the fields that will be sent through the API.
- Configure Information and Alert Management options.
- Retrieve the push URL.
Using the push URL
After configuring the realtime source parameters, a URL path containing a push API key appears. This path, appended to your workspace's base URL, is where the platform will expect data to be sent after publication.
The data is expected to be sent in JSON format: - As a single JSON object for a single record - An array of JSON objects to push multiple records at once
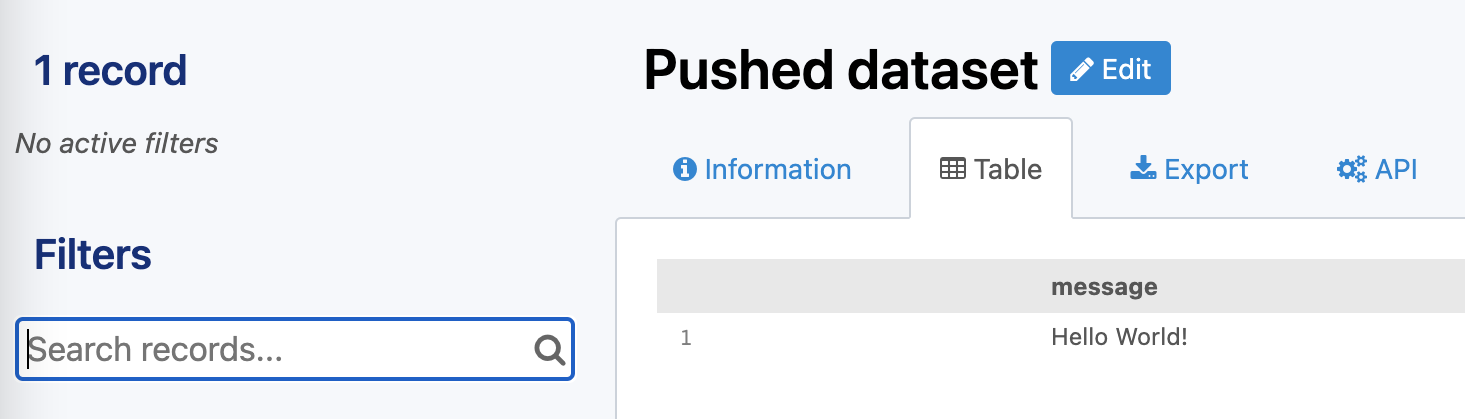
A minimal example of the API usage for a dataset with a single field named message, using curl, would be:
curl -XPOST <WORKSPACE_URL>/api/push/1.0/<DATASET_ID>/<RESOURCE_ID>/push/?pushkey=<PUSH_API_KEY> -d'{"message":"Hello World!"}'
Here is the resulting dataset:
A minimal example with the same dataset, using the array form to send multiple records at once would be:
curl -XPOST <WORKSPACE_URL>/api/push/1.0/<DATASET_ID>/<RESOURCE_ID>/push/?pushkey=<PUSH_API_KEY> -d'[{"message":"¡Hola Mundo!"},{"message":"Hallo Welt!"}]'
If the records have been received correctly, the server will send the following response.
{
"status": "OK"
}
If an error happens while trying to push a record, the response will specify the error.
Pushing a field of type file
To push a field of type image, a JSON object containing the base64-encoded content and the MIME type of the file needs to be sent:
{
"image_field": {
"content": "BASE64 data",
"content-type": "image/jpg"
}
}
Updating data by defining a unique key
Sometimes, it is useful to update the existing records instead of pushing new ones. To set up such a system with the Opendatasoft platform, the fields used as a unique key must be marked as so.
Procedure
To mark fields as a unique key, do the following:
- In the preview area of the Processing tab, click the wheel button of the field of your choice
- Select Unique ID
- Save and publish the dataset
If a new record whose key value is equal to an existing record is pushed, the new record will overwrite the old record.
Example
A dataset tracks the number of copies available for each book in a public library:
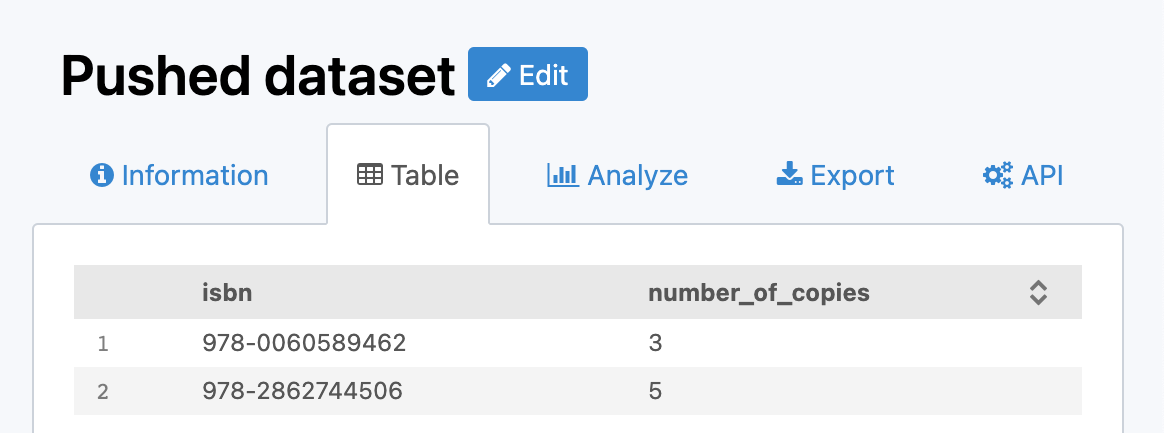
Suppose that this dataset contains two fields:
isbn, representing the ISBN number of the booknumber_of_copiestracking the current number of copies available in the library
In that case, it does not make sense to add one record for each new value of number_of_copies. Instead, it would be better to set the new number_of_copies value to the record corresponding to the book isbn.
In this example, the unique key would be isbn because the rest of the data is linked to individual books, and these books are identified by the ISBN.
If your dataset has isbn as the unique key and contains these two records:
[
{
"isbn": "978-0060589462",
"number_of_copies": 3
}, {
"isbn": "978-2862744506",
"number_of_copies": 5
}
]
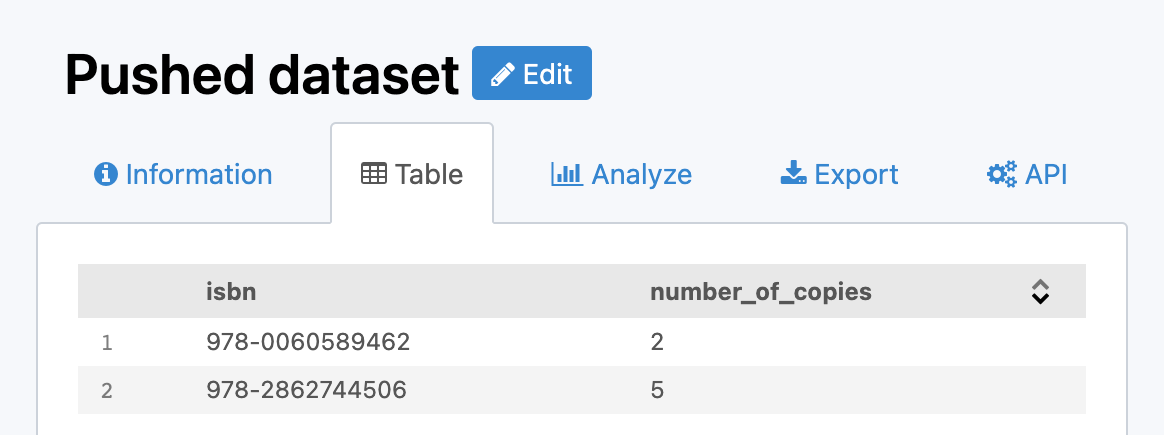
If somebody borrows a copy of Zen and the Art of Motorcycle Maintenance, and you push the following record:
{
"isbn": "978-0060589462",
"number_of_copies": 2
}
You will still have two records, the first one being updated with the new value:
Deleting data
Two endpoints allow for deleting pushed records. One that uses a record's values and one that uses a record's ID.
Deleting data using a record's values
To delete a record using its values, POST the record as if you were adding it for the first time, but replace /push/ with /delete/ in the Push URL. If your Push URL path is /api/push/1.0/<DATASET_ID>/<RESSOURCE_ID>/push/?pushkey=<PUSH_API_KEY>, then use instead /api/push/1.0/<DATASET_ID>/<RESSOURCE_ID>/delete/?pushkey=<PUSH_API_KEY>.
Here is an example to delete the record we pushed earlier:
curl -XPOST <WORKSPACE_URL>/api/push/1.0/<DATASET_ID>/<RESOURCE_ID>/delete/?pushkey=<PUSH_API_KEY> -d'{"message":"Hello World!"}'
Deleting data using the record ID
If you know the ID of the record you want to delete, make a GET request to the Push URL by replacing /push/ with /<RECORD_ID>/delete/:
curl -XGET <WORKSPACE_URL>/api/push/1.0/<DATASET_ID>/<RESOURCE_ID>/<RECORD_ID>/delete/?pushkey=<PUSH_API_KEY>
Delete all of the data from a dataset
The Push API does not allow you to empty a dataset of all its data, and this is not a method we recommend (instead, for example, an FTP server might be more appropriate).
However, as a workaround, you can use the Automation API to accomplish the same thing with a few API calls.
To delete the data, you simply need to unpublish and re-publish the dataset.
See the documentation for the Automation API for help unpublishing and publishing a dataset and for the URLs to call for these operations:
- Unpublish a dataset:
curl -X POST <DOMAIN_URL>/api/automation/1.0/datasets/<DATASET_UID>/unpublish?pushkey=<PUSH_API_KEY>
- Publish a dataset:
curl -X POST <DOMAIN_URL>/api/automation/1.0/datasets/<DATASET_UID>/publish?pushkey=<PUSH_API_KEY>
<DOMAIN_URL>/api/automation/1.0/datasets/?dataset_id=<DATASET_ID>Get notified in case of inactivity
If you expect a system to push data to the platform often, you may want to be notified if the platform has received no record in a while.
To get notified, perform the following steps:
- In Catalog > Datasets, click the desired dataset
- Display the desired source
- Click Alert management
- In the dialog box that opens, configure the alerting parameters:
- Select the Alerting check box
- Enter a threshold in minutes in the Inactivity alert check box
If a time span greater than the threshold has occurred during which no record has been received, you will receive an email.
Unpublishing and disabling the API
When unpublishing your dataset, existing records are not kept for the next time the dataset is published.
To avoid getting new data, perform the following steps:
- In Catalog > Datasets, click the desired dataset
- On the desired source, select

This will prevent the usage of the push API but will not affect existing data. If data is pushed while push is disabled, no data will be added, and an error will be sent.
Recovering data
In the event of data loss, for example, when the dataset has been unpublished or when a processor has been misconfigured, there is a possibility of recovering the lost records.
Every record received is backed up and eligible for recovery.
To recover eligible records, perform the following steps:
- In Catalog > Datasets, click the desired dataset
- On the desired source, select

How did we do?
How to find your workspace's IP address
Processing data
Table of Contents
- Using scheduling to keep a dataset up to date
- Adding a source
- Specifying scheduling interval
- Pushing realtime data