 Premier pas avec Opendatasoft
Premier pas avec Opendatasoft
 Explorer et utiliser les données
Explorer et utiliser les données
Explorer le catalogue et les jeux de données
Explorer un catalogue de jeux de données
Contenu d'un jeu de données
Filtrer des données dans un jeu de données
Introduction à l'API Explore
Introduction à l'API Automation
Présentation de l'API WFS
Télécharger un jeu de données
Recherchez vos données avec l'IA (recherche vectorielle)
Créer des cartes et des graphiques
Création de graphiques avancés avec l'outil Graphiques
Présentation de l'interface Cartes
Configurez votre carte
Gérez vos cartes
Réorganiser et regrouper les couches dans une carte
Création de cartes multicouches
Partagez votre carte
Navigation dans les cartes créées avec le créateur de Cartes
Renommer et enregistrer une carte
Créer des pages avec l'éditeur de code
Archivage d'une page
Gérer la sécurité d'une page
Créer une page avec l'éditeur de code
Pages de contenu : idées, conseils et ressources
Comment insérer des liens internes sur une page ou créer une table des matières
Partager et intégrer une page de contenu
Comment dépanner les cartes qui ne se chargent pas correctement
Créer des pages avec le Studio
Créer du contenu avec Studio
Ajouter une page
Publier une page
Modifier la mise en page
Configurer des blocs
Aperçu d'une page
Ajouter du texte
Ajout d'un graphique
Ajouter un bloc image à une page Studio
Ajouter un bloc de carte dans Studio
Ajouter un bloc de carte choroplèthe dans Studio
Ajout d'un bloc de carte de points d'intérêt dans Studio
Ajouter un indicateur clé de performance (KPI)
Configurer les informations d'une page
Utiliser des filtres pour améliorer vos pages
Affiner les données
Gérer l'accès aux pages
Comment modifier l'url d'une page Studio
Intégrer une page Studio dans un CMS
Les visualisations
Gérer les visualisations sauvegardées
Configurer la visualisation Calendrier
Explorer les différentes visualisations d'un jeu de données
Configurer la visualisation Images
Configurer la vue personnalisée
Configurer la visualisation Tableau
Configurer la visualisation Carte
Comprendre le regroupement automatique dans les cartes
Configurer la visualisation Analyse
 Publier des données
Publier des données
Publier vos jeux de données
Créer un jeu de données
Créer un jeu de données à partir d'un fichier local
Créer un jeu de données avec plusieurs fichiers
Création d'un jeu de données à l'aide de connecteurs dédiés à des services distants spécifiques
Créer un jeu de données avec des fichiers multimédias
Fédérer un jeu de données Opendatasoft
Publier un jeu de données
Publication de données à partir d'un fichier CSV
Formats de fichiers pris en charge
Valorisez les données de mobilité grâce au GTFS et autres formats
Gérer les configurations de vos jeux de données
Suppression automatique des enregistrements
Configuration de l'export de jeux de données
Consulter l'historique du jeu de données
Configurer l'info-bulle
Actions et états des jeux de données
Limites des jeux de données
Définir un modèle de données
Comment Opendatasoft gère les dates
Comment et où Opendatasoft gère les fuseaux horaires
Comment trouver l'adresse IP de votre espace de travail
Maintenir les données à jour
Traiter des données
Traduire un jeu de données
Comment configurer une connexion HTTP à l'API de France Travail
Décider quelle licence convient le mieux à votre jeu de données
Formats de fichier source
Fichiers OpenStreetMap
Shapefiles
Fichiers JSON
Fichiers XML
Fichiers de feuille de calcul
Fichiers RDF
Fichiers CSV
Fichiers MapInfo
Fichiers GeoJSON
Fichiers KML
GeoPackage
Sauvegarde et partage de connexions
Connecteur Airtable
Connecteur Amazon S3
Connecteur ArcGIS
Connecteur de stockage Azure Blob
Connecteurs de base de données
Connecteur Jeu de données de jeux de données (espace de travail)
Connecteur Eco Counter
Connecteur Feed
Connecteur Google BigQuery
Connecteur Google Drive
Comment trouver la clé API Open Agenda et l'URL Open Agenda
Connecteur JCDecaux
Connecteur Netatmo
Connecteur OpenAgenda
Connecteur Realtime
Connecteur Salesforce
Connecteur SharePoint
Connecteur US Census
Connecteur WFS
Connecteur Databricks
Connecteur Waze
Les moissonneurs
Moissonner un catalogue
Moissonneur ArcGIS
Moissonneur ArcGis Hub Portals
Moissonneur CKAN
Moissonneur CSW
Moissonneur FTP avec CSV de métadonnées
Moissonneur Fédération Opendatasoft
Moissonneur Quandl
Moissonneur Socrata
Moissonneur data.gouv.fr
Moissonneur data.json
Les processeurs
Qu'est-ce qu'un processeur et comment l'utiliser ?
Processeur Ajouter un Champ
Processeur Calculer la distance géographique
Processeur Concaténer du texte
Processeur Convertir des degrés
Processeur Copier un Champ
Processeur Corriger les formes géographiques
Processeur Créer un point géo
Processeur Décoder les entités HTML
Processeur Décoder un polyline Google
Processeur Dédupliquer des champs multivalués
Processeur Supprimer un enregistrement
Processeur Déplier le tableau JSON
Processeur Déplier les champs à valeur multiples
Processeur Expression
Processeur Extraire du HTML
Processeur Extraire les URLs
Processeur Extraire la plage de bits
Processeur Extraire d'un objet JSON
Processeur Extraire du texte
Processeur Fichier
Processeur GeoHash en GeoJSON
Processeur de jointure géographique
Processeur Géocoder avec ArcGIS
Processeur Géocoder avec la BAN (France)
Processeur Géocoder avec PDOK
Processeur Géocoder avec le Census Bureau (États-Unis)
Processeur Masquage géographique
Processeur Récupérer les coordonnées d'une adresse 3 mots
Processeur Adresse IP vers Coordonnées Géo
Processeur Tableau JSON vers multivalué
Processeur Joindre des jeux de données
Processeur Méta-expression
Processeur Géocodeur Nominatim
Processeur Normaliser le Système de Projection
Processeur Normaliser une URL
Processeur Normaliser les valeurs Unicode
Processeur Normaliser une date
Processeur Filtrage du polygone
Processeur Remplacer le texte
Processeur Remplacer avec une expression régulière
Processeur Récupérer les divisions administratives
Processeur Définir le fuseau horaire
Processeur Simplifier les formes géo
Processeur Ignorer les enregistrements
Processeur Séparer le texte
Processeur Transformer des colonnes de booléens en champs multivalués
Processeur Transposer des colonnes en lignes
Processeur WKT et WKB en GeoJSON
Processeur what3words
La fonctionalité Formulaire de Collecte de Données
À propos de la fonctionnalité Formulaire de Collecte de Données
Formulaires de collecte de données associé à votre espace de travail Opendatasoft
Créez et gérez vos formulaires de collecte de données
Partager et modérer vos formulaires de collecte de données
Metadonnées des ensembles de données
![]() Analyser l'utilisation de mes données
Analyser l'utilisation de mes données
S'impliquer : partager, réutiliser et réagir
Découvrir et soumettre des réutilisations de données
Partage via les réseaux sociaux
Commenter via Disqus
Suivre les mises à jour d'un jeu de données
Partager et intégrer des visualisations de données
Statistiques d'utilisation
Introduction à l'utilisation des statistiques de vos espaces de travail
Analyser l'activité des utilisateurs
Analyser les actions
Détails sur les champs spécifiques du jeu de données ods-api-monitoring
Comment compter les téléchargements d'un jeu de données sur une période spécifique
Analyser l'utilisation des données
Analyser l'utilisation des jeux de données
Analyser l'activité du back office
Utilisation de la fonctionnalité de lignage des données
 Gérer les groupes et utilisateurs
Gérer les groupes et utilisateurs
Gérer les limites
Gérer les utilisateurs
Gestion des utilisateurs
Définition de quotas pour des utilisateurs individuels
Gérer les demandes d'accès
Inviter des utilisateurs sur le portail
Gérer les espaces de travail
 Gérer mon portail
Gérer mon portail
Configurer mon portail
Configurer les pages du catalogue et du jeu de données
Configuration d'un catalogue partagé
Partager, réutiliser, communiquer
Personnaliser l'URL de votre espace de travail
Gestion des informations juridiques
Connecter Google Analytics (GA4)
Paramètres régionaux
Gérer le suivi
Navigabilité et apparence
Personnaliser votre portail
Personnaliser les thèmes du portail
Comment personnaliser mon portail selon la langue courante
Gérer les thèmes du jeu de données
Configurer les visualisations de données
Configurer la navigation
Ajouter des ressources
License et quotas
Monitoring de la licence et des quotas de votre espace de travail
Licences et quotas de votre espace de travail
Gérer la sécurité
Configurer la politique de sécurité générale de votre portail
L'onglet Sécurité d'un jeu de données
Mapping de vos groupes Opendatasoft avec votre annuaire (via SSO)
Authentification unique (SSO) avec OpenID Connect
Authentification unique (SSO) avec SAML
Paramètres
Langues prises en charge par Opendatasoft
Configuration des paramètres du compte
Gestion des identités
Comprendre les notifications reçues avec vos autorisations
Gestion des notifications
Gestion des clés API
Accessibilité chez Opendatasoft
Enregistrement des applications
Vérification du quota du compte
Connecteur Databricks

Cet article suppose que vous connaissez les bases de l’utilisation de Databricks. Si ce n'est pas le cas, veuillez vous référer à la documentation de Databricks .
Ce connecteur vous permet d'utiliser SQL pour interroger votre instance Databricks via un SQL Warehouse ou un Cluster .
Pour configurer le connecteur Databricks, vous devrez d'abord obtenir les informations trouvées dans Databricks. Ce sera sur le panneau de configuration de l'entrepôt ou du cluster, selon celui auquel vous avez l'intention de vous connecter. Avec ces informations en main, vous pouvez terminer la configuration du connecteur.
Champs de connecteur
Voici les champs de configuration du connecteur :
Nom de domaine | Obligatoire/facultatif |
Hôte | Requis |
Port | Requis |
HTTP path | Requis |
Personal access token | Requis |
Catalogue | Requis |
Schéma | Facultatif |
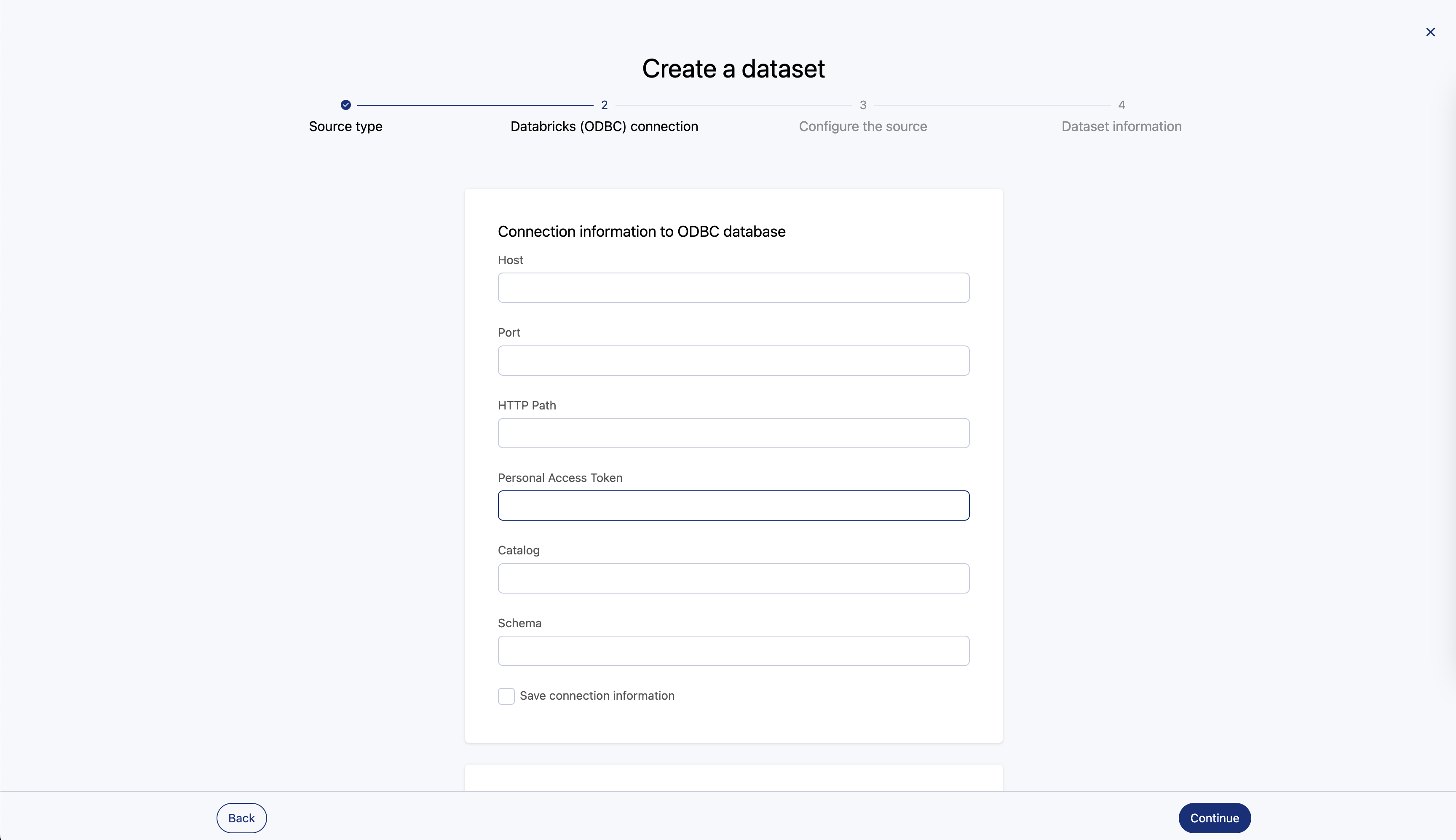
Suivez ces étapes pour connecter votre portail de données à Databricks :
Connectez-vous à un warehouse Databricks
Les deux premières étapes ci-dessous concernent la collecte des informations nécessaires à la connexion d'Opendatasoft à Databricks. Les deux dernières étapes consistent à définir les données que vous souhaitez interroger.
1. Récupérer les champs Hôte, Port et Chemin HTTP
Accédez à l’onglet Détails de votre connexion Databricks Warehouse :
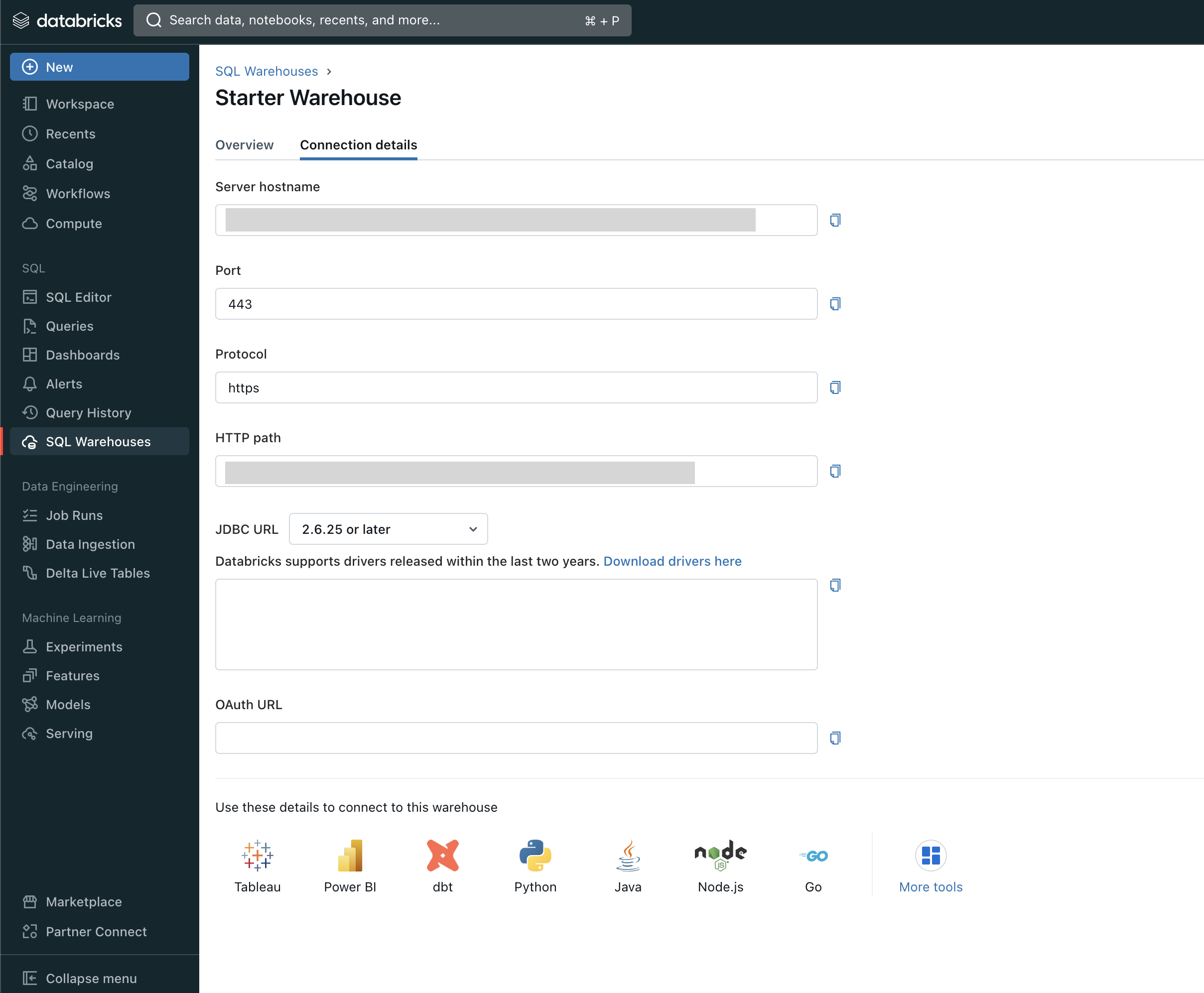
Là, vous devez copier ce qui suit :
- Hôte
- Port (443 par défaut)
- HTTP path
2. Récupérer un personal access token
Pour permettre à Opendatasoft de communiquer avec votre SQL warehouse Databricks, vous devez fournir un personal access token fonctionnel. Il peut être créé directement sur l'espace de travail Databricks .
3. Récupérer les noms de catalogue et de schéma
Pour rechercher le catalogue et le schéma, accédez à la page Catalog Explorer (cliquez sur Catalog dans la barre latérale) et ouvrez le catalogue que vous souhaitez interroger.
4. Effectuez la requête SQL
Vous devez remplir les champs de requête en utilisant les noms de catalogue et de schéma. Voici la documentation qui traite de chacun de ces champs.
Par exemple, si j'ai choisi d'utiliser le catalogue samples mais que je n'ai pas précisé que je souhaitais utiliser son schéma nyctaxi pour requêter la table trips, la requête ressemblerait à :
SELECT * FROM nyctaxi.trips(Facultatif) Se connecter à un cluster
Vous devez disposer d'un cluster de calcul personnel ou partagé.
Si vous accédez à la page de configuration de votre cluster > Option avancée > JDBC/ODBC , vous verrez tous les détails de connexion que vous devez utiliser pour vous connecter à ce cluster spécifique.
Vous pouvez les utiliser et suivre les mêmes étapes que les instructions ci-dessus.